Can LLMs like ChatGPT accurately make translations better than humans? What options of LLMs do we have to work with? Learn more about using generative AI to make translations in multiple different languages.
The Background
At the time of writing this post, I have been working with data for nearly a decade and within localization for 2 years. I have experience with various forms of artificial intelligence including, but not limited to, clustering, classification, and sentiment analysis. Machine translation (MT) is commonly used in localization. Think of it like entering some text into Google Translate and requesting it to be translated into another language. From my experience, machine translation generally is correct 80% of the time, but still requires a human to review/fix mistranslations.
With the rise of large language models (LLMs) like ChatGPT and Google Bard, we might be able to get closer accuracy to human translation by providing additional context to the LLMs (like definitions and parts of speech).
The Hypothesis
LLMs work with a prompt based input. This means the more information and context you can provide in the prompt, the better the output from the LLM. Given a sample of English terms, their definitions and their parts of speech, we would like to see if LLMs can produce better results at translating terms into different languages. The two LLMs we will be using are GPT (through a Jupyter Notebook via an OpenAI API) and Vertex AI (through Google BigQuery’s ML.GENERATE_TEXT function). The latter of which requires a lot more setup, but can be run directly in your querying console with SQL.
Using LLMs to Translate
GPT
We start off by installing the OpenAI python library in our jupyter notebook
import sys
!{sys.executable} -m pip install openai
Import pandas to work with dataframes. Import the previously installed openai library and set your API key. Read in your data into a dataframe. If you’d like to follow along, the data that I’ll be working with can be found here.
import pandas
import openai
openai.api_key = "YOUR_API_KEY"
# read in your data
df = pd.read_csv('mydata/terms_sample.csv')In a list, set the languages you’d like the word to be translated into.
languages = ['Spanish (Spain)', 'Spanish (LatAm)', 'German', 'Italian', 'Japanese', 'Chinese (S)', 'French']Create a function that iterates over the rows in your dataframe and languages in your list to translate the terms respectively. The prompt will be entered into the “messages” section. We will be using GPT 3.5 and setting the temperature to a very small number to ensure that we get precise/less creative responses from the LLM.
def translate_terms(row, target_language):
"""Translate the terms"""
user_message = (
f"Translate the following english term with the into {target_language}: '" + row['Term'] +
"'.\n Here is the definition of the term for more context: \n" + row['Definition'] +
"'.\n Here is the part of speech of the term for more context: \n" + row['Part of speech'] +
".\n Please only translate the term and not the definition. Do not provide any additional text besides the translated term."
)
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful translation assistant that translate terms into other languages given an english term and defintion."},
{"role": "user", "content": user_message},
],
max_tokens=50,
n=1,
temperature=0.1
)
return response['choices'][0]['message']['content']The final step is to iterate the translation function over the dataframe for each language in the list and create a new column for the terms in those respective languages. Please find the full code for your reference.
# Apply the function to the DataFrame
for language in languages:
df[language+'_terms'] = df.apply(translate_terms, axis=1, args=(language,))
Google Bard / text-bison / Vertex AI
We will be using the ML.GENERATE_TEXT function within Google’s text-bison model to translate the same terms as before. This process does take a little more resources to set up, but once up and running, we will be able to call an LLM directly in our SQL query.
Setup
I will not be providing a detailed setup guide as everyone’s Google Cloud infrastructure is unique to their needs. Rather, I’ll provide a high level overview with links on how to get the ball rolling.
- Ensure that there is a Vertex AI User role enabled to access your service account.
- Set up a remote cloud connection
- BigQuery uses a CLOUD_RESOURCE connection to interact with your Vertex AI endpoint or Cloud AI service.
- Go to BigQuery
- To create a connection, click add Add data, and then click Connections to external data sources.
- In the Connection type list, select BigLake and remote functions (Cloud Resource).
- In the Connection ID field, enter a name for your connection.
- Click Create connection.
- Click Go to connection.
- In the Connection info pane, copy the service account ID for use in a later step.
- Create an LLM Model with the remote cloud connection
- You should now be able to run your LLM Model using the ML.GENERATE_TEXT function. I would recommend looking into the function’s arguments to understand what parameters are required.
- Upload your data into your billing project so it can be queried.
The Code
The code that was used to generate the translations can be found below. Due to a combination of my own limitations and the restrictions of our query engine, I decided to individually run the code for each language (manually replacing the bolded text) instead of looping over the languages ARRAY like I did with the previous jupyter notebook.
DECLARE USER_MESSAGE_PREFIX STRING DEFAULT (
'You are a helpful translation assistant that translate terms into other languages given an english term and defintion.'|| '\n\n' ||
'Translate the following english term into French. Please do not translate the definition as well.'|| '\n\n' ||
'Term: '
);
DECLARE USER_MESSAGE_SUFFIX DEFAULT (
'\n\n' || 'Here is the definiton of the term for more context: '|| '\n\n'
);
DECLARE USER_MESSAGE_SUFFIX2 DEFAULT (
'\n\n' || 'Here is the part of speech of the term for more context: '|| '\n\n'
);
DECLARE USER_MESSAGE_SUFFIX3 DEFAULT (
'\n\n' || 'French translation of term:'
);
DECLARE languages ARRAY<string>;
SET languages = ['Spanish (Spain)', 'Spanish (LatAm)', 'German', 'Italian', 'Japanese', 'Chinese (S)', 'French'];
SELECT
ml_generate_text_result['predictions'][0]['content'] AS generated_text,
ml_generate_text_result['predictions'][0]['safetyAttributes']
AS safety_attributes,
* EXCEPT (ml_generate_text_result)
FROM
ML.GENERATE_TEXT(
MODEL `YOUR_BILLING_PROJECT.YOUR_DATASET.YOUR_LLM`,
(
SELECT
Term,
Definition,
USER_MESSAGE_PREFIX || SUBSTRING(TERM, 1, 8192) || USER_MESSAGE_SUFFIX || SUBSTRING(Definition, 1, 8192) || USER_MESSAGE_SUFFIX2 || SUBSTRING(Part_of_speech, 1, 8192) || USER_MESSAGE_SUFFIX3 AS prompt
FROM
`YOUR_BILLING_PROJECT.YOUR_DATASET.terms_sample`
),
STRUCT(
0 AS temperature,
100 AS max_output_tokens
)
);Interpreting the Results
Qualifier: I do not speak any of these languages besides English so take my conclusions with a grain of salt.
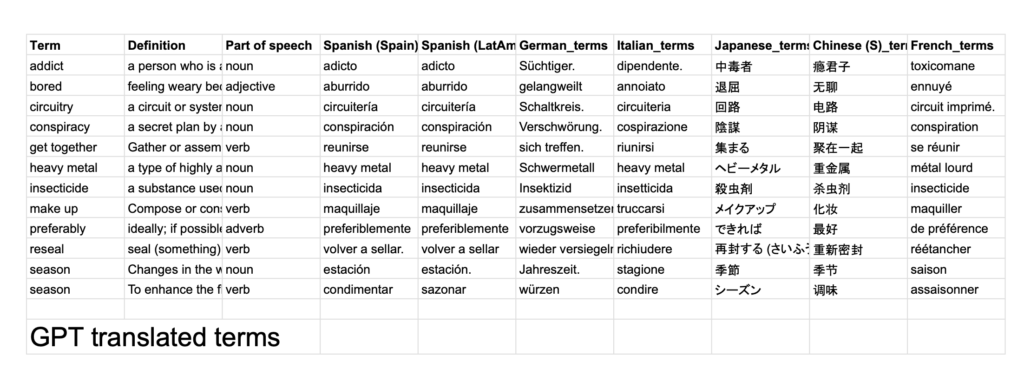
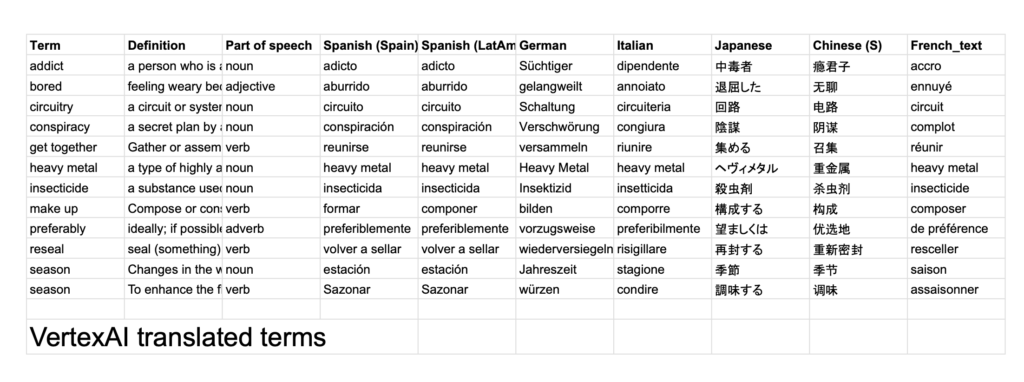
The results can be found here. Some findings that I made note of:
- 47 / 84 (56%) of translations by both LLMs were exactly the same
- GPT included a period (.) at the end of the word often. By removing these, the match percentage increases to 63%.
- It seems that Japanese and French were the most unaligned translations between the two LLMs.
- GPT understood the term “make up” as make-up (ie. cosmetics), which is concerning because the it seems like it didn’t leverage the definition and part of speech for that term before making a translation.
- This could be because my prompt structure was not optimal. For example, I could’ve provided the definition before the term to allow the LLM to process that information first.
- Heavy metal (proper noun) seems to be literally translated by GPT, especially in German, where it was translated to a term that does not correspond with the music genre
Ultimately I’d say both LLMs have their advantages and disadvantages. GPT is easy to setup and run in python, while Vertex AI understands prompts clearer and takes in all the context before making a translation. I think it’s fair to say that the LLMs do a much better job than regular machine translation because they are able to process additional context in their prompts. Let me know what you think. Could I have made things better?